
König minus Mann plus Frau ergibt Königin. Was sich auf den ersten Blick wie eine der ungeliebten Textaufgaben aus dem Mathematikunterricht anhört, ist ein Beispiel für eine Rechenoperation, die bei der Sprachverarbeitung durch maschinelles Lernen eingesetzt wird. Der Blick hinter die Kulissen hilft uns zu verstehen, wie Künstliche Intelligenz lernt, worum es in einem Text geht.
In einem früheren Beitrag haben wir bereits die Grundzüge der Echtzeit-Datenanalyse im Kundendialog beleuchtet. Heute steigen wir einen Schritt tiefer in die dazu erforderlichen Grundlagen ein.
Grundsätzliches: Klassifikation und Regression
Maschinelles Lernen beruht im Wesentlichen darauf, Muster in Daten zu erkennen. So werden bei der Regression auf Basis der vorhandenen Daten allgemeingültige Beziehungen zwischen Variablen hergestellt. Dieses Verfahren entspricht in etwa einer Vorhersage. Bei der Klassifikation geht es dagegen darum, eine vorhandene Datenmenge in unterschiedliche Gruppen einzuteilen. Um zum Beispiel in einer Gruppe von Elementen die Dreiecke von den Kreisen zu trennen, kommt es darauf an, das Wesentliche dieser beiden Objekte zu unterscheiden.
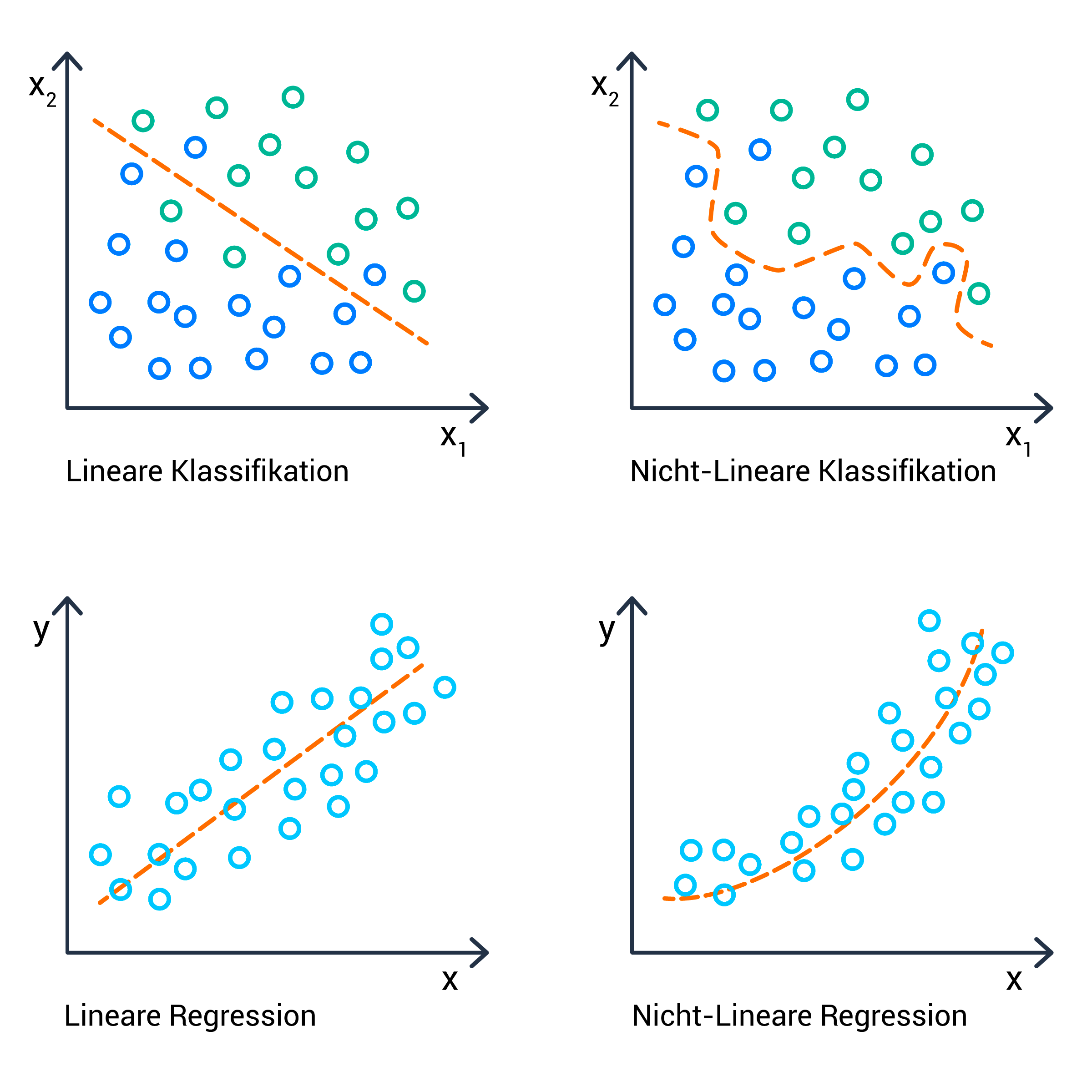
Bei der Klassifikation können z.B. lineare und nicht-lineare Modelle eingesetzt werden. Dabei vermag eine nicht-lineare Klassifikation die vorhandenen Daten feiner aufzulösen – allerdings birgt sie auch Gefahren: Passt man das Modell zu sehr an die Trainingsdaten an, kommt es leicht zum sogenannten Overfitting. Testet man das Model ausschließlich mit dem Trainingsmaterial, erreicht man ein sehr gutes Ergebnis – aber es besteht die Möglichkeit, dass die Klassifikation von neuen Beispielen fehlschlägt.
Vokabular: Wörter als Tokens
Bislang haben wir sehr vereinfacht von „Daten“ gesprochen. Doch besteht der Text, den zum Beispiel ein Kunde als Anfrage an einen Bot sendet, aus unmittelbar für eine KI nutzbare Daten? Nein! Um aus Wörtern und Sätzen einen Datensatz zu generieren, mit dem sich sinnvoll arbeiten lässt, müssen wir Repräsentationen (Stellvertreter) finden. Dazu bestimmen wir zunächst die Grundbausteine des Texts, die Tokens.
Ein Token besteht in der Regel aus zusammenhängenden Zeichen, die durch Leerzeichen, Zeilenumbrüche oder Tabulatoren getrennt sind. Auch Satzzeichen können als Tokens verstanden werden. Jedes Wort ist also ein Token, aber nicht jeder Token ist auch ein Wort! Sehen wir uns drei Beispielsätze und die daraus generierten Tokens an:

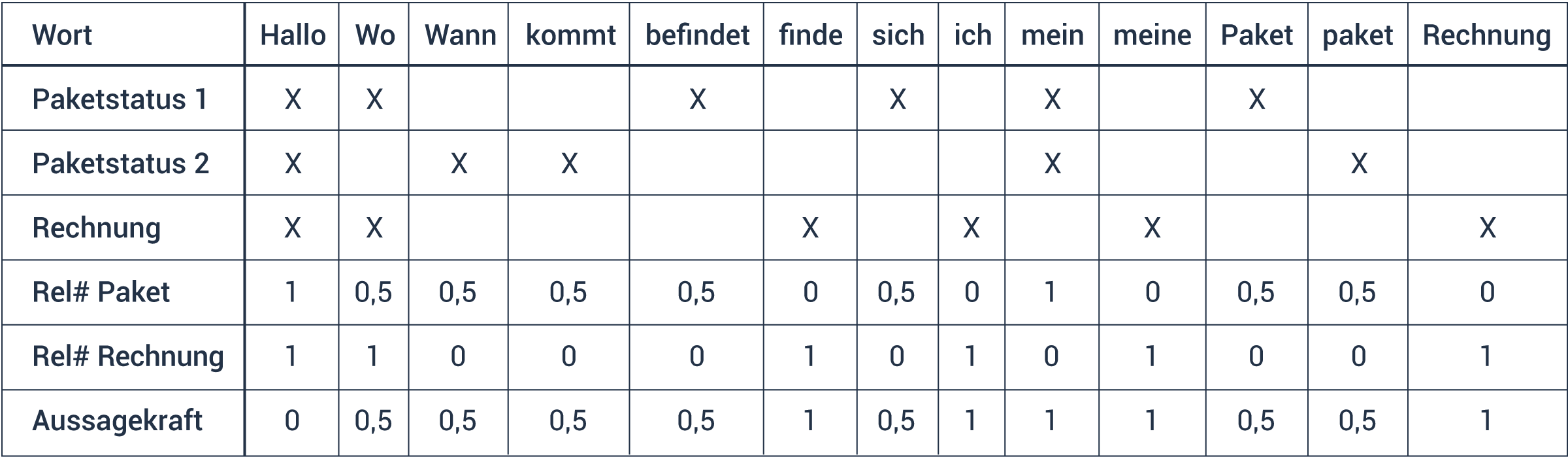
Aus diesen Tokens können wir nun das gesamte Vokabular aller drei Texte zusammenstellen:

Vereinfachung: Preprocessing
Wir kennen jetzt sämtliche Tokens aus unseren drei Texten. Wenn man jedoch genauer hinschaut, sieht man, dass 'Paket' und die falsche Schreibweise 'paket' unnötigerweise zwei verschiedene Tokens sind. Daher wandeln wir im Preprocessing alle Zeichen zu Kleinbuchstaben um, um das Vokabular zu reduzieren. Ein weiterer möglicher Schritt ist das Reduzieren von verschiedenen Tokens auf einen gemeinsamen Wortstamm, also das Beseitigen von Varianten, die sich aus Deklination und Konjugation ergeben (Stemming). Zudem lassen sich im Kontext der Anwendung oft benutzte Synonyme wie Paket, Päckchen oder Lieferung zusammenfassen. Und die Interpunktion kann in vielen Fällen komplett entfallen.
Darüber hinaus können sogenannte Stopwords entfernt werden. Dazu zählen vor allem Funktionswörter, die in erster Linie für den korrekten Satzbau nötig sind, aber zur Kerninformation eines Textes wenig beitragen, also zum Beispiel Pronomen wie 'mein', Artikel wie 'das', aber auch Partikel wie 'oh'. Einen Hinweis darauf, ob ein Wort „wichtig“ ist, kann das Tf-idf-Maß geben: Es gewichtet ein Wort nicht nur nach seiner Vorkommenshäufigkeit (term frequency) im Text, sondern bezieht auch die inverse Dokumenthäufigkeit (inverse document frequency) in die Betrachtung mit ein. So werden die in der natürlichen Sprache grundsätzlich sehr häufig vorkommenden Wörter wie Pronomen oder Artikel schließlich geringer gewichtet.
Generell ist dieses Preprocessing aber immer mit Bedacht anzuwenden, da es eine Klassifikation auch erschweren kann. Zudem kann ein inhaltlich auf den ersten Blick entbehrlicher Token wie zum Beispiel das Satzzeichen '!' oder das Partikel 'oh 'später sehr hilfreich sein, um zum Beispiel in der ergänzenden Sentimentanalyse die Stimmungslage des Kunden zu erkennen.
Repräsentation: Tokens als Vektoren
Wir haben nun aus einem Set an vorhandenen Texten eine Liste von Tokens extrahiert. Im einfachsten Fall könnten wir nun jedes Wort mathematisch repräsentieren, indem wir ihm einfach einen beliebigen, innerhalb der Wortliste einmaligen Zahlenwert zuordnen. Durch dieses als Bag-Of-Words (BOW) bezeichnete Verfahren erhalten wir allerdings lediglich ein Schlagwortverzeichnis, das nichts über die Beziehung der Wörter untereinander aussagt.
Auf Basis des maschinellen Lernens mit neuronalen Netzen können wir dagegen das wesentlich komplexere Word2Vec-Verfahren einsetzen, mit dem sich Beziehungen zwischen Wörtern abbilden lassen. Hier wird jedes Wort durch Zahlen repräsentiert, die einen Vektor in einem mehrdimensionalen Raum beschreiben.
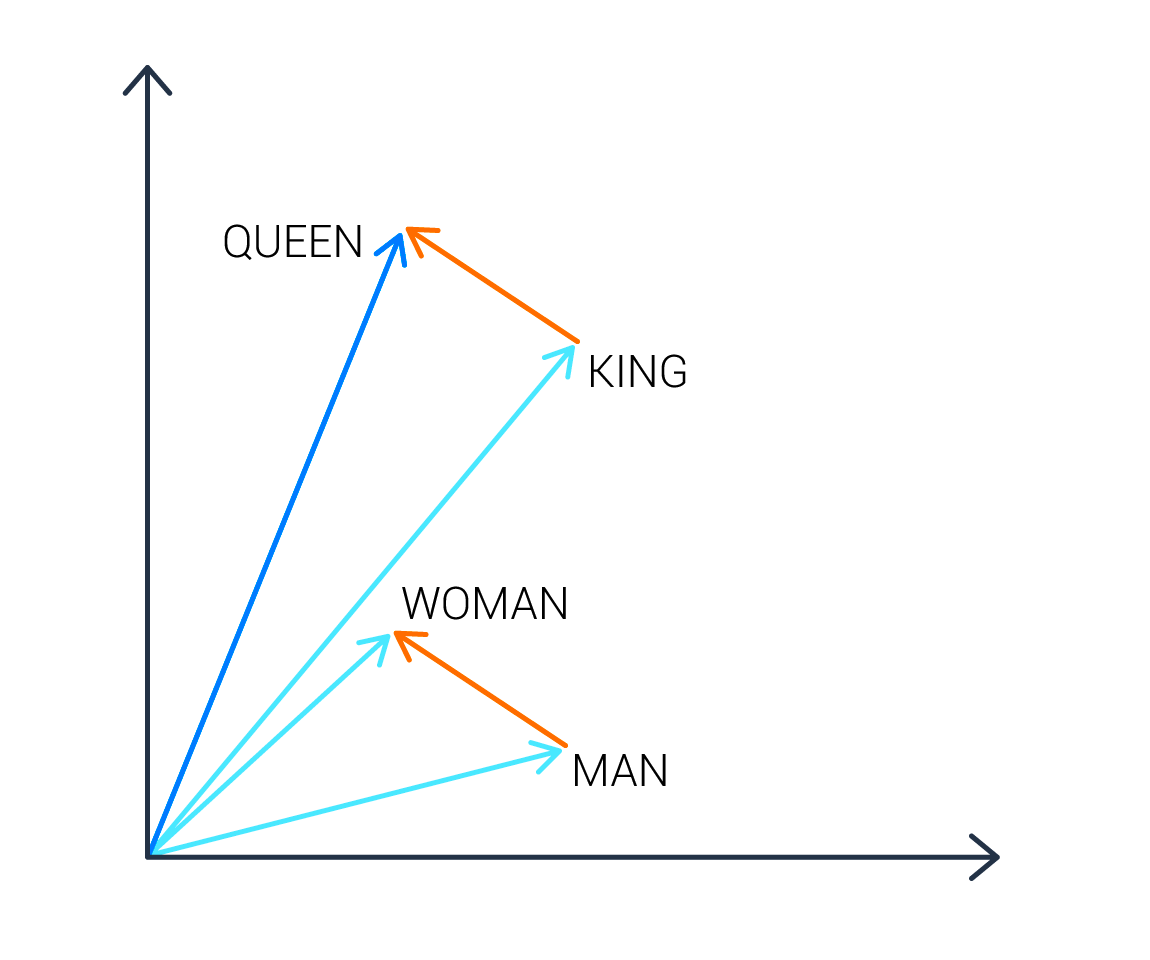
Da sich die Beziehungen zwischen den Vektoren in diesem Raum mathematisch errechnen lassen, können wir recht einfach Wortpaare finden, die sich beispielsweise ähnlich oder unähnlich sind. In unserem Beispiel verhält sich im Vektorraum der Token 'King' zu 'Queen' wie 'Man' zu 'Woman'. Auch einfache Rechenoperationen lassen sich erfolgreich durchführen: So ergibt 'King' minus 'Man' plus 'Woman' das Ergebnis 'Queen'.
Ein Gefühl für die Möglichkeiten dieses Tools gibt Ihnen der auf Word2Vec basierende Semantic Calculator, mit dem Sie verschiedene Operationen auf Basis ausgewählter englischsprachiger Wörterbücher durchspielen können.
Die Komplexität der Aufgabe bestimmt das Verfahren
Zum Abschuss stellt sich die Frage, welches der beiden Verfahren bzw. Modell am besten bewährt. Die Antwort lautet wie so oft: es kommt darauf an! Herkömmliche Algorithmen, die auf ein „Bag-of-Words“ angewendet werden, führen bei kleinen Datenmengen schnell und einfach ans Ziel. Bei komplexeren Aufgaben mit großen Datenmengen zeigen sich die Vorzüge des maschinellen Lernens. Bei der Herangehensweise sind deshalb die Erfahrung und das Augenmaß der KI-Architekten gefragt, um nicht mit Kanonen auf Spatzen zu schießen.













